One of the most popular document formats to share and write data is PDF. You may come across millions of situations where you must extract table from PDFs or scanned documents. There are online tools available that provide PDF to Excel conversion but that’s not the ultimate solution. These tools may get the job done, but you still would need to manually pick data that is important to you. Not to mention how daunting this task would be but imagine the number of hours you would waste doing a task that can be easily automated. Fortunately, DocAcquire deals with such tasks seamlessly. You can extract relevant data from pdf without wasting your precious time.
Tables are one of the primary structuring elements in a document like PDFs. To reuse the table data appropriate extraction methods are needed. Table data extraction from PDF’s is the process of retrieving structured data arranged in a tabular format from PDF documents. Many PDF files contain important data stored in tables, such as reports, invoices, and spreadsheets, which are difficult to extract due to the non-editable nature of PDFs. The method to extract table from PDFs helps convert this data into usable formats like CSV, Excel, or databases for easy analysis.
In today’s digital landscape, efficient table data extraction from PDFs is essential for businesses seeking to unlock valuable insights and streamline workflows. By using extract table from PDF methods and tools, organizations can unlock valuable data, enhance productivity, and make more data-driven decisions. This blog explores the importance of extracting table data from PDFs, common challenges faced, different methods for extraction, and a detailed guide on using DocAcquire platform for seamless data extraction.
Before diving into how to extract table from PDFs, let’s look at why this process is so essential for organizations and professionals:
Pdf’s have become the most widely used mode of communication between systems, individuals, and companies. It is considered a standard version of documents. Some of the popular use cases of PDF documents in the business world are:
Extracting table data from PDFs can be challenging due to several factors. Here’s a look at the main challenges:
The huge volume of PDFs exchanged daily means that there is a need to find a solution that can extract tables from PDF automatically and quickly. Also, spending time to extract and export the data from pdf into any other third-party system will be a costly affair. The primary issue that leads to other bigger problems in data extraction from pdf is that PDFs were designed only as a data output format and not as a data input format. It helps in printing the data formatting exactly as you see it on your screen. However, as far as a table format is concerned, a PDF does not have any internal structure for it. And that’s the reason it is a cumbersome task to extract tables from PDF. You can find many online tools that claim to extract data from tables. However, most of these end up truncating the data or distorting the internal table structure. Hence, the data you extract becomes practically useless, as you manually must input it into any other third-party system.
One of the most common solutions for extracting data from PDF is to use an OCR. However, before you go and start the data extraction process there are various things that need to be considered. Firstly, whether you are processing an image-based document or text file. Most of the OCRs work fine with text-based images, however, they struggle with processing image-based documents. Some of the OCRs that can be helpful are Amazon Textract, Google Vision, etc. OCR or optical character recognition technology, which helps to recognize the data inside a file and converts it into a searchable and editable form.
But is that enough? For a business that requires processing thousands of documents in a month, a simple OCR will sort the problem of data processing. Well, yes! If you are ready to handle the tons of data after extraction, then a simple OCR will do. But you can save hours of hard work and effort by leveling up and switching to automated solutions provided by DocAcquire. DocAcquire helps to Extract table data from a variety of document types like; Invoices, Purchase Orders, Proof of Delivery, Contracts, Insurance Claims, Bill of Lading, and many more. It provides a flexible integration engine to extract and cleanse tabular data by using out-of-the-box powerful and intuitive tools. We have been heavily investing to deliver an engaging and simple user experience that enables our users to automate invoice workflows and seamlessly export the data to other systems.
Several methods can be employed to effectively extract tables from PDFs, ranging from manual-copy pasting to using sophisticated software tools. Here are some of the most effective approaches:
1. Manual Extraction:
It refers to the process of retrieving and organizing data that appears in table format within a PDF document without relying on automated tools. This involves copying or retyping the data into another application, such as a spreadsheet, to recreate the table format.
Pros:
Cons:
2. Tabula:
Tabula is a free, open-source tool crafted by journalists for journalists, specially built in order to extract tables from PDF files. Users can easily navigate its intuitive interface to select and extract table data, with the option to convert to CSV or Excel formats.
Pros:
Cons:
3. Excalibur:
Excalibur simplifies PDF table extraction using the Camelot library. With customizable parameters, users can define table regions for optimal extraction. It supports exporting tables to CSV and Excel, catering to diverse needs. Excalibur makes it easy to extract tables from PDFs and convert PDF tables to Excel.
Pros:
Cons:
4. pdfplumber:
pdfplumber is a Python library designed for extracting tables from PDFs. Leveraging pdfminer as its foundation, pdfplumber offers a robust PDF parsing engine capable of handling diverse PDF layouts and formats.
Pros:
Cons:
5. PDFTables:
PDFTables is an online tool, specializes in PDF table extraction, enabling users to extract tables from PDFs and convert them into Excel, CSV, or XML formats. It quickly finds tables within PDF documents and converts PDF table to Excel and offers various formats for the converted data.
Pros:
Cons:
DocAcquire is a robust software solution designed for efficient table data extraction from PDFs. It can extract tabular data from PDFs and can help you to automate your data extraction without any hassle. Here’s how you can leverage Doc Acquire:
DocAcquire is a powerful, cloud-based platform that leverages artificial intelligence to automate the process of data extraction from a wide range of documents. It is designed to transform manual data entry tasks into automated workflows, thereby saving time, reducing errors, and enhancing customer experience.
The platform can extract data from any document type, including invoices, and integrates seamlessly with various business systems such as ERP, CRM, and Finance. It uses machine learning to recognize and extract key data from complex documents, ensuring accurate and efficient data capture.
In addition to data extraction, DocAcquire offers verification and enrichment features to ensure perfect data flows into your business systems and makes it easy for exceptions to be handled even faster.
Used across various sectors including Accounts Payable, Logistics, and Insurance, DocAcquire is trusted by many organizations for its ability to reduce manual effort, processing time, and cost. It is a reliable solution for businesses looking to streamline their data extraction processes and improve operational efficiency.
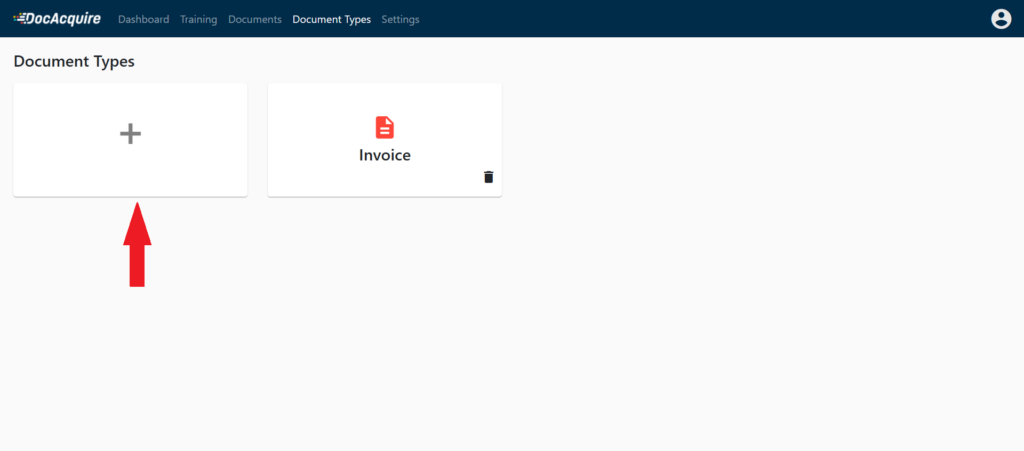
1. Create a Document Type
Go to the Documents Tab and click on the “Plus Icon” to add a document type.
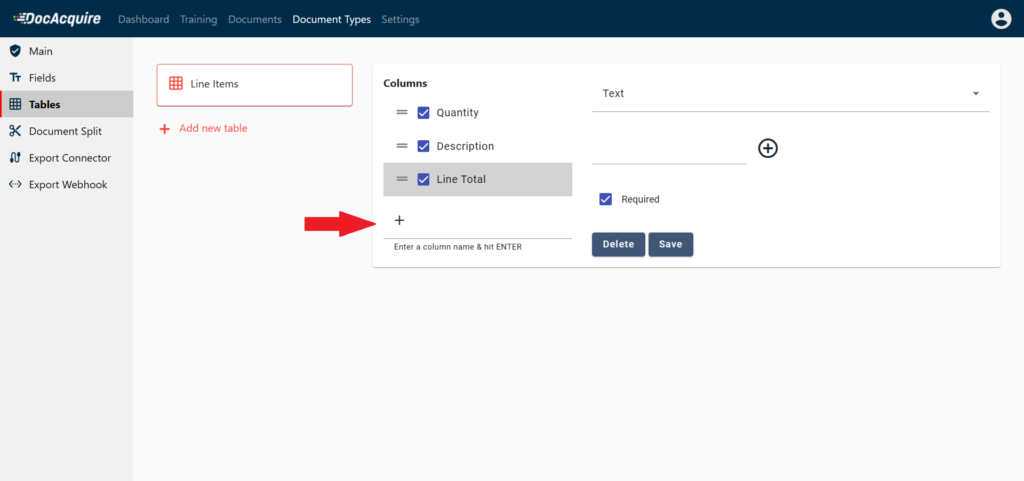
2. Create line items for the Document Type
Go to the Tables tab in the side navbar and define rows for them. Click here to know more. You can specify the data type of each of the line items you create.
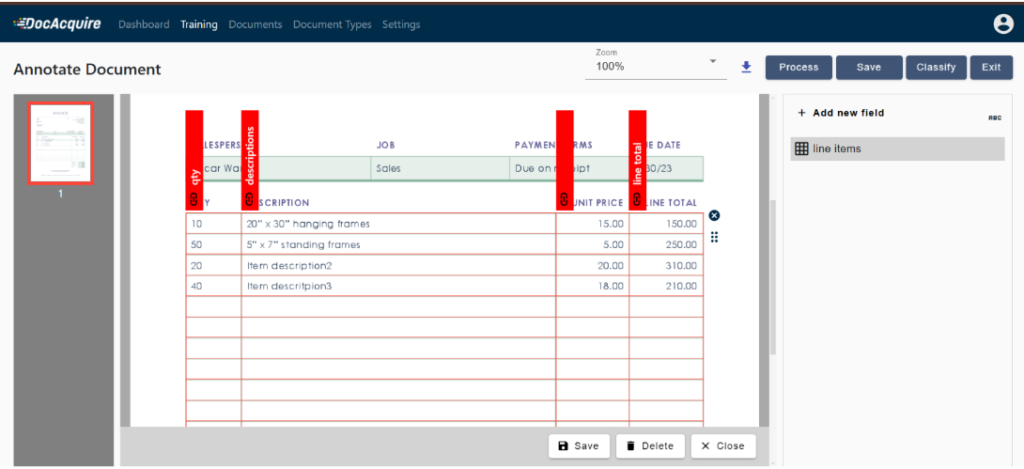
3. Train the document for table extraction.
4. Uploading and processing PDF documents for data extraction.
Select the desired document type. This ensures accurate processing and data extraction based on the specific document template.
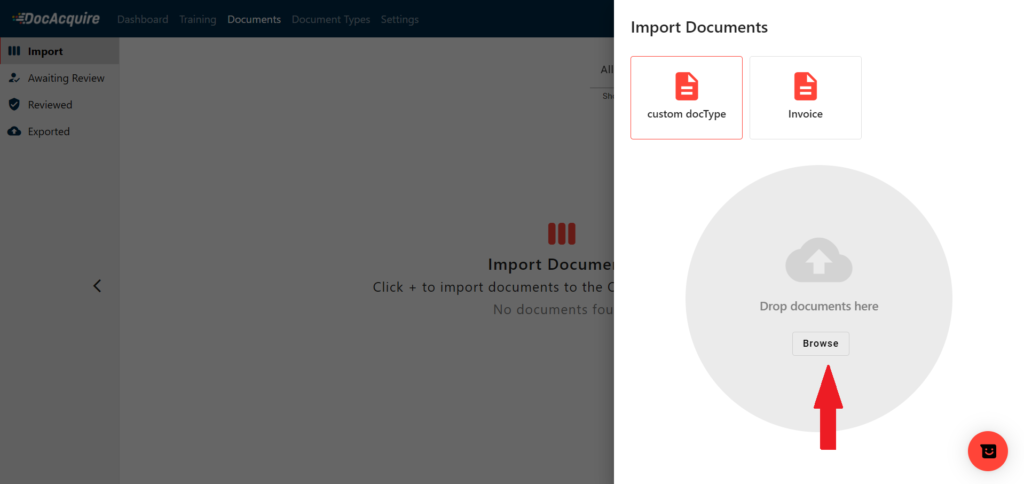
5. Verifying, manually extracting, and exporting extracted data for further analysis:
DocAcquire provides flexibility to review, and export extracted data. In addition to automated extraction, users can also manually extract tables by clicking the Extract Table button, enabling precise control over data capture when automated recognition might need adjustments.
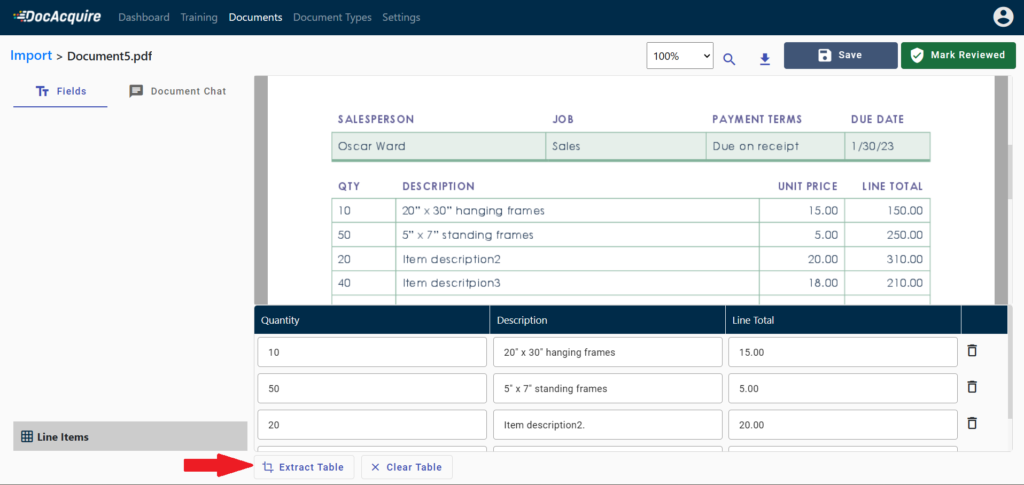
6. View the excel sheet.
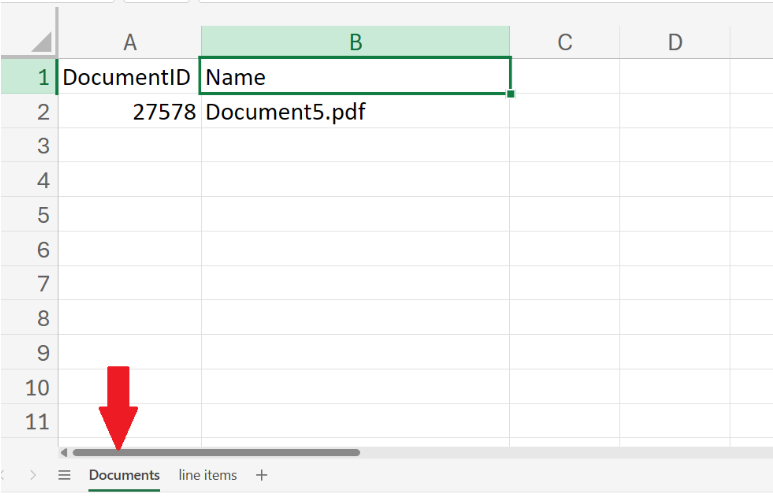
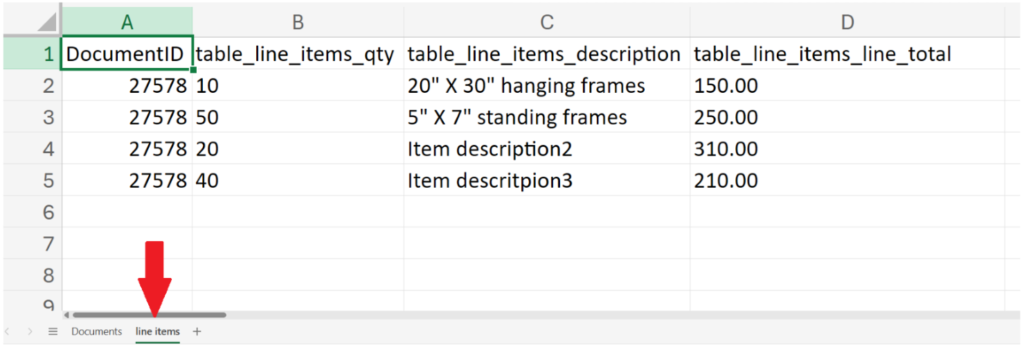
Check out a quick demo of DocAcquire to see these steps in action.
1. How accurate is table data extraction from PDFs using DocAcquire?
DocAcquire leverages advanced AI algorithms to achieve high accuracy in extracting table data from PDFs. However, accuracy may vary based on the complexity of the document layout.
2. Is DocAcquire suitable for extracting tables from scanned PDFs?
Yes, DocAcquire can extract tabular data from scanned PDFs using OCR (Optical Character Recognition) technology. It can detect text from images and convert it into machine-readable formats, allowing you to capture data from tables even in non-digital (scanned) PDFs.
3. How does DocAcquire handle multi-page tables?
DocAcquire can extract tables that span across multiple pages by using an intelligent table append feature. It ensures that multi-page tables are extracted as one coherent table, saving time and maintaining accuracy during the data extraction process.
4. Do I need programming skills to use DocAcquire?
No, DocAcquire is designed to be user-friendly and does not require programming skills. However, for advanced customization or integration with other systems, some technical knowledge may be helpful.
5. How long does it take to set up DocAcquire for extracting tables from PDFs?
The setup time for DocAcquire depends on the complexity of your extraction requirements. Our team can assist you in configuring the software to meet your specific needs efficiently.
In conclusion, extracting tables from PDFs is a critical process for accessing and utilizing valuable data within documents. Despite the challenges posed by PDF formats, innovative solutions like DocAcquire empower businesses to automate and streamline data extraction workflows efficiently.
We hope this article helped you get started with getting table data from invoices and purchase orders. If you want a helping hand with the setup reach out to us.
Want to try DocAcquire? Just let us know.
Back to blog
In today’s fast-paced business environment, organizations are increasingly relying on automation to handle massive volumes of documents. However, manual data entry and document processing are...
Read article
What is PDF? PDF (Portable Document Format) is a file format that is used to present and exchange documents reliably, independent of software, hardware, or operating system. PDF was invented by...
Read article
In today’s fast-paced business world, companies are always seeking innovative ways to streamline operations, improve efficiency, and foster better communication—both internally and...
Read article
Do your accounts payable department give you a headache? Are you procrastinating on sorting your invoices? You are not alone! Most business owners loathe the invoice handling process, it may seem...
Read article
The Covid-19 pandemic brought “the new normal” along with it. People now don’t go out unnecessarily, businesses are working remotely, schools and colleges are taking online classes, and...
Read article
One of the most popular document formats to share and write data is PDF. You may come across millions of situations where you must extract table from PDFs or scanned documents. There are online...
Read article